

多年来碰到 PDF 表格、图片扫描件表格无法复制问题,这个工具都可以完美解决。
前言
前几天我推荐了一款文档对比工具 Calliper ,收到了不少粉丝的喜欢,特别是头条的粉丝,于是我再次了解看看 Calliper 的官网,看看是否还有什么好用的工具,还真发现了 PDFlux,一款能解决接触 PDF 文档多年以来棘手问题的生产力工具。
关于 PDFlux
PDFlux 是一款强大的富格式文档的解析工具,基于 AI 识别技术,可以深度解析 PDF 文档、扫描件 PDF 和图片等文档格式,复制这些包含富格式的内容,特别是精准识别并提取这些文档中的表格,让我们方便地粘贴到 Word、Excel 中。
目前 PDFlux 提供 windows / macOS 的客户端下载,当然我们也可以使用功能一致的在线版本,无需下载安装,打开浏览器就能使用,特别适合偶尔应急使用。
PDFlux 的功能特点
- 支持 PDF、扫描件 PDF 和图片等多种难以复制数据的文档格式
- 精准识别文档的章节目录,甚至可以智能生成章节目录
- 可精准识别文字、表格、图片内容,并在线复制、修改、翻译
- 智能优化扫描件中印章、手写、歪斜、模糊等干扰
- 支持多人在线协同批注 PDF 文档内容
PDFlux 上手使用体验
拿到一份 PDF 文档或一个图片扫描件,最大的困扰的就是里面的内容无法编辑和复制,下面看看怎么用 PDFlux 来解决这个问题。
识别文档段落、表格,轻松复制
在数据提取模块中,PDFlux 将文档解析成文本段落、表格等元素块信息,鼠标悬浮即可复制、修改、翻译、收藏相应的元素块信息,同时也支持复制整页内容。
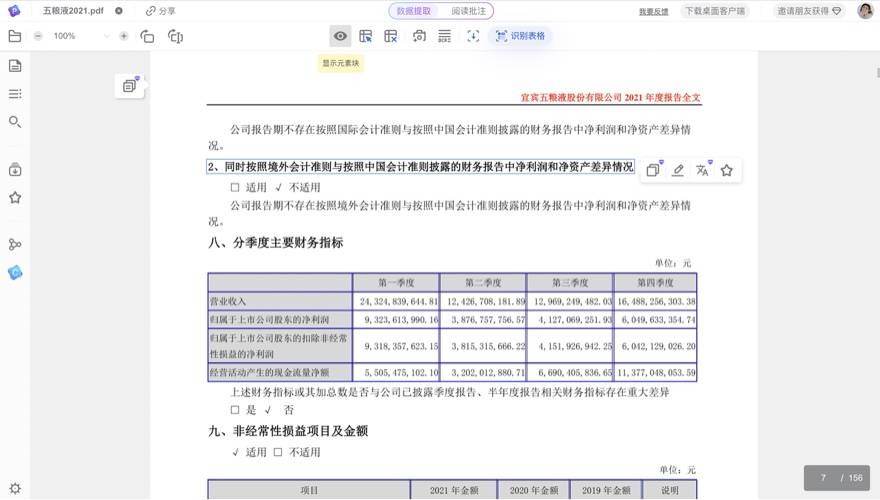
识别精准
PDFlux 的识别效果非常精准,尤其是表格内容的识别,令人惊艳!甚至可以把跨页表格内容自动合并,再进行比较。比如下图红框就直接识别成“7581388.92”:
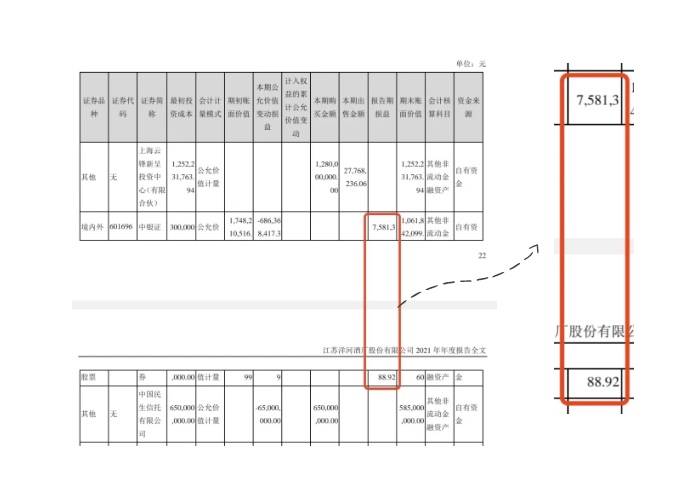
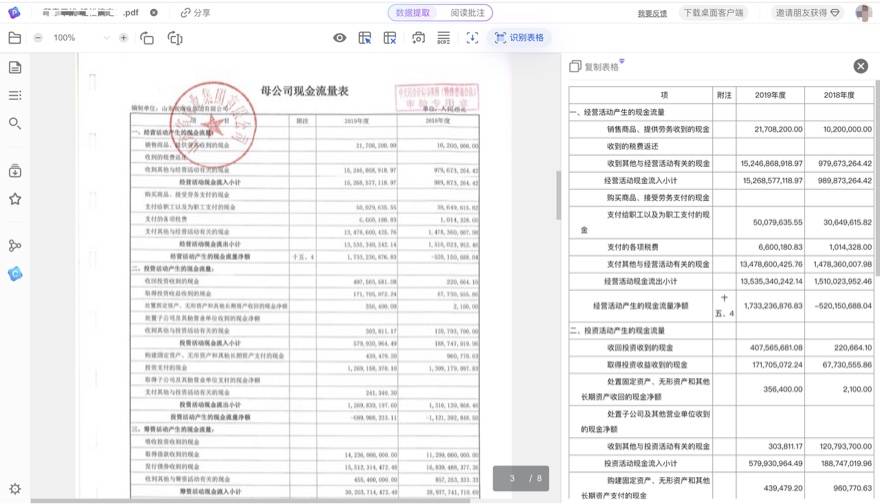
排版复杂的表格,拥挤紧凑的表格内容和无线框的表格内容也可以轻松识别,都不是问题。
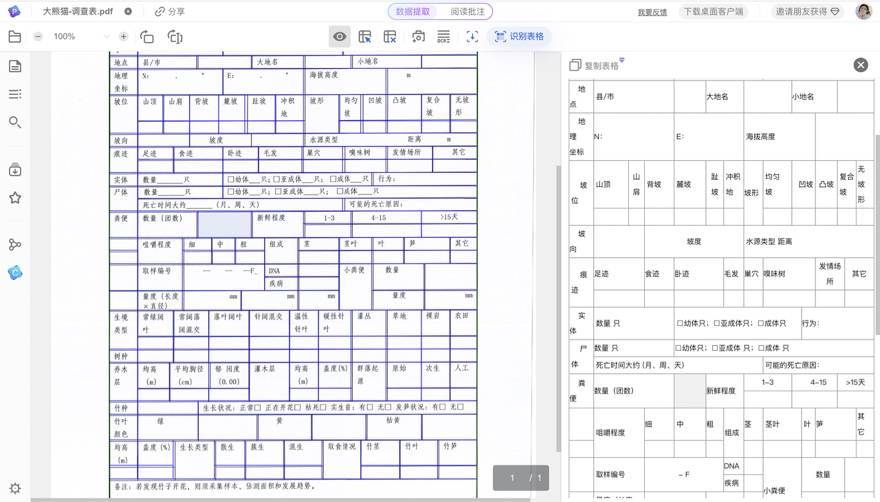
有时工作中会遇到一些文档歪斜、字迹模糊、印章干扰的扫描件,需要花大量的时间手工识别和录入。现在用 PDFlux 就可以轻松识别了。
复制便捷、支持翻译
关闭显示元素块功能,就可以支持快捷键智能选中词语、句子和段落,支持自动识别和合并跨行、跨栏、跨页的内容,支持对选中内容一键复制和翻译,这在浏览外文论文等文档时尤为实用,让 PDF 内容提取也能像使用 Word 一样丝滑顺畅,简单方便。
开发接入支持
作为一款效率工具,我们可以直接下载 PDFlux 安装包或者直接使用在线版,能满足我们的日常工作需求,如果企业有大量的识别提取需求,PDFlux 也支持两种方式接入:
- SaaS服务:通过调用 API 接口,批量将PDF文档解析为文本段落、表格、图片等内容块的序列
- PDFlux SDK:开发组件,可快速构建文档智能应用,提供文档展示、搜索、信息抽取、审核、多文档关联、批注、协同、阅读行为统计等各种功能,可无缝接入已有系统
如果要处理的文档涉及机密,开发接入也支持私有化部署,文档在自己的服务器上处理,安全有保障。
免费使用说明
和之前推荐的文档内容对比神器 Calliper 一样,PDFlux 也是由国产软件厂商庖丁科技开发,也是一款基础功能免费,高阶功能需要“钻石”的 PDF / 图片中富文本、表格提取应用。
按官网的说明,大部分功能都是免费的,个别功能因为耗费计算资源,需要消耗少量钻石(1元=10钻石),每日登录和邀请好友都会有钻石奖励。






